Dies ist eine Auswahl von Projekten, für die ich Software geschrieben habe. Aufgrund von Vertraulichkeitsvereinbarungen können nicht alle Projekte aufgelistet werden.
Common Crawl Host Web Graph Sample 2022
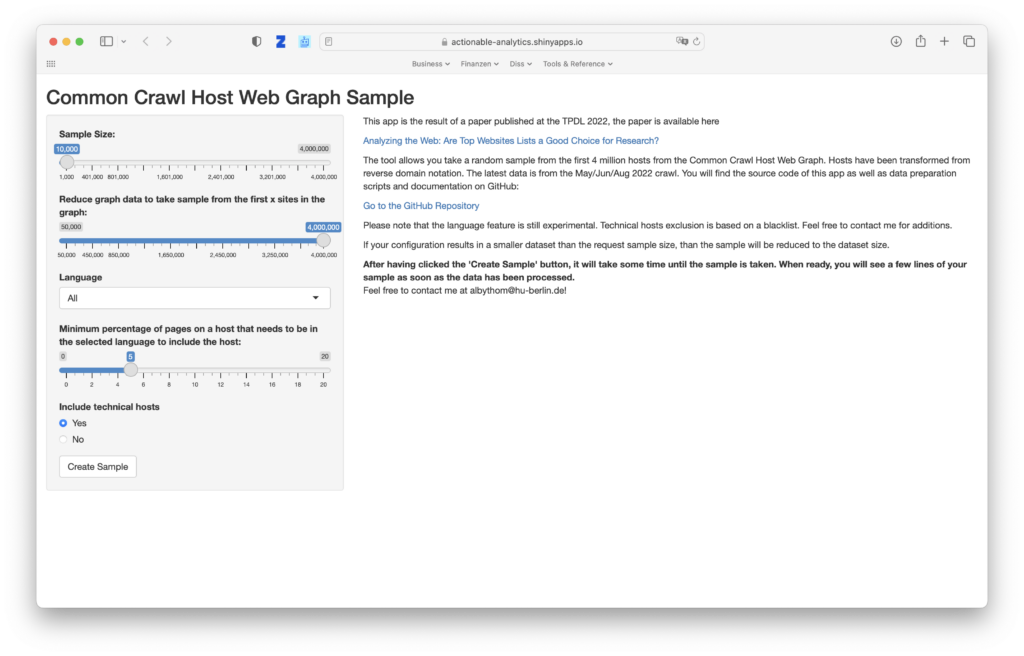
A tool written for my paper Analyzing the Web: Are Top Websites Lists a Good Choice for Research?.
Corona Dashboard / Eigenes Projekt 2020
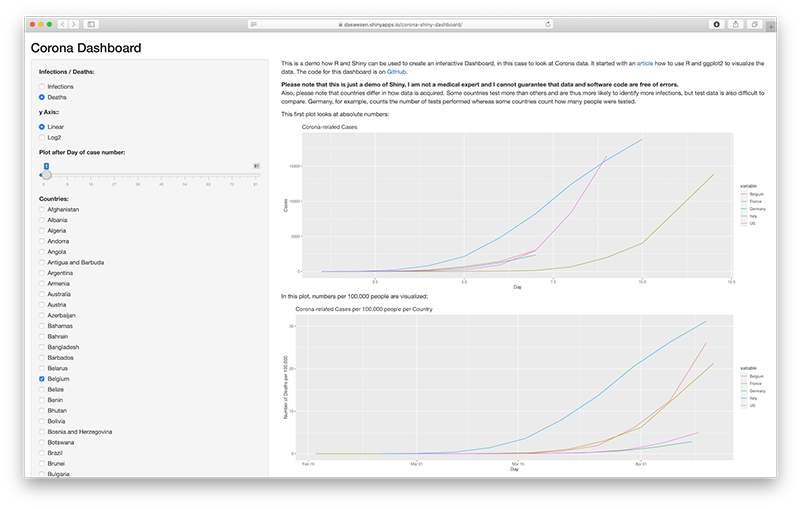
Mit R, ggplot2 und Shiny erstelltes Dashboard mit aktuellen Zahlen aus verschiedenen Datenquellen zum Thema Corona.
Liquiditäts-Simulation / Euler Hermes 2020

Eine in R geschriebene Shiny-App, die anhand von Parametern und Zufallsvariablen potentielle Liquiditätsszenarien in Echtzeit darstellt. Sie wurde 2020 mit dem Digitaler Leuchtturm-Award Versicherungen der SZ und Google prämiert.
Personas basierend auf Amazon Rezensionen / Interone 2018
Anhand der Profile der Rezensenten mit ihren Rezensionen zu unterschiedlichen Produkten wurden Cluster von Nutzern mit ähnlichen Käufen identifiziert. In R geschrieben.
Actionable Dashboard / Interone 2018

Ersetzte ein vorher vorhandenes Dashboard, das mit sinnlosen Zahlen gefüttert worden war. In diesem neuen Dashboard wird die Sichtbarkeit in Medien und Suchmaschinen für bestimmte Themen anhand von Sistrix- und Feed-Daten angezeigt und mit der Zielerreichung handlungsrelevant verknüpft. Außerdem wurde die User Experience anhand von Geschwindigkeit ermittelt. Alle Daten wurden gebenchmarked mit Marktbegleitern und enthielten zudem Prognosen. Ich habe das Dashboard konzipiert und einen Teil der Daten-Akquise, -Aggregation und -Analyse in R geschrieben.
Supra, ein ML-basierter Assistent für Suchmaschinenoptimierung / Interone 2018

Ein ML-basierter Assistent für die Suchmaschinenoptimierung, der das Ranking für Suchbegriffe und die dazugehörende Seite analysiert und Handlungsvorschläge unterbreitet. Hat einen Webby Award in der Kategorie BEST USE OF MACHINE LEARNING gewonnen. Ich habe Teile davon in Python und R geschrieben.
Google-Analytics-basierte Personas / Interone 2017
Auf Basis von Google Analytics-Rohdaten und demographischen Daten werden Personas aus Seitenabruf-Sequenzen erstellt und die Wahrscheinlichkeit für Geschlecht, Alter und Interessen mittels Naive Bayes berechnet. Die Software wurde in R geschrieben. Dieses Projekt ist nicht zu verwechseln mit dem Ansatz, datenbasierte Personas mithilfe von Assoziationsregeln zu erstellen.
Next Best Action für Automotive-Website / Interone 2017
Basierend auf Adobe Analytics-Rohdaten wurde der apriori-Algorithmus verwendet, um die Next Best Action in Form einer Website vorzuschlagen. Geschrieben in R.
Lunch Roulette mit Amazon Echo / Interone 2017
Kleine Spielerei, mit der man anhand von Sprache einen Lunchpartner in der Firma finden konnte. Geschrieben in PHP.
spiegel.de Paid Article-Klassifikation / Eigenes Projekt 2016
Auf Basis der Spiegel.de-Daten wurde eine Classifier geschrieben, der anhand der ersten 50 Wörter eines Artikels vorhersagen konnte, ob ein Artikel kostenpflichtig sein würde oder nicht. Lediglich eine Programmierübung, es wäre aber spannend gewesen, die Daten mit den tatsächlichen Kaufmustern der Artikel in Verbindung zu bringen. Es waren aber auch schon so Muster erkennbar, welche Artikel eher kostenpflichtig sind 🙂 Geschrieben in Python.
Kindle Clippings Manager / Eigenes Projekt 2010-2011

Der Amazon Kindle ist ein spannendes Gerät, unter anderem auch, weil man seine Notizen zu Textstellen exportieren kann. Leider erhält man dann aber nur eine Datei mit allen Notizen, die man jemals gemacht hat, so dass man einzelne Notizen länger suchen muss. Dieses Problem löst der Kindle Clippings Manager. Die Applikation wurde in RealBasic geschrieben. Schaffte es auf die CD der PC World. Die Software wird nicht mehr gepflegt.
AdShadow / Eigenes Projekt mit Partner 2009
Crawling des deutschen Webs und Suche nach AdSense-IDs. Geschrieben in Perl, Suchmaschine realisiert mit swish-e.
Klassifikation von Online Shops / PayPal 2008
Ein Crawler identifiziert Online Shops und erkennt das darunter liegende System, die Zahlungssysteme sowie die Art der Waren, die verkauft werden. Anhand von passenden Suchanfragen und Suchmaschinen-Rankings wird die Popularität des Shops berechnet. Die Daten dienten zur Berechnung der Marktanteile von Shop- und Zahlungssystemen in verschiedenen Branchen. Geschrieben in Perl.
Similar Search / Ask.com 2007
Basierend auf der “Distanz” von Wikipedia-Artikeln habe ich eine Similar Search für die internationalen Suchmaschinen von Ask.com geschrieben. Sie wurde in Deutschland, Frankreich, Italien, Niederlande und Spanien ausgerollt. Die Software wurde in Perl, C und mit Shell-Skripten geschrieben.
Blogosphere / Seekport 2006

Für mein Buchprojekt Web 2.0 habe ich die deutsche Blogosphäre gecrawlt und Teile davon visualisiert. Innerhalb des Graphen wurden Influencer idenzifiziert und die Entwicklung von Stories innerhalb des Graphen verfolgt. Geschrieben in Perl und R.
Blog Search / Seekport 2005
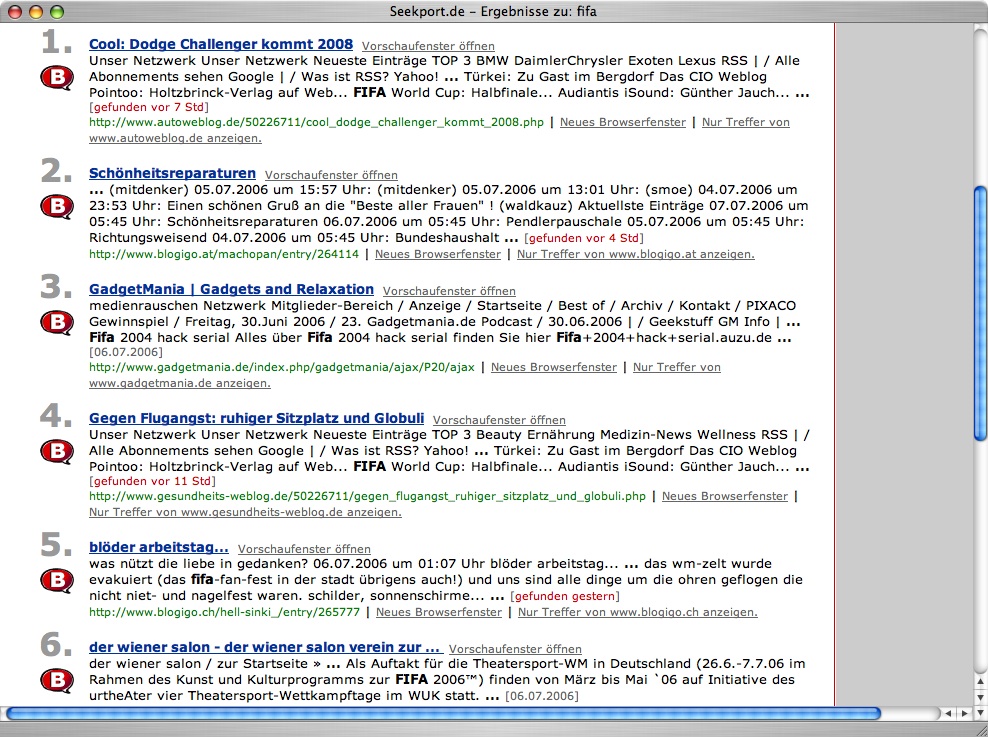
Ein eigener Crawler erkennt Blogs automatisch und nutzt deren Feed-Funktion, um weitere Blogs zu finden und den Such-Index automatisch zu aktualisieren. Die Software wurde in Perl, C und mit Shell-Skripten geschrieben.
Homographen-Identifikation in der Suchanfrage / Seekport 2005
Zunächst manuell gesammelt, später durch computerlinguistische Methoden identifiziert. Schaffte es sogar in die Heise News. In Perl geschrieben.
Paid Submissions / Lycos 2003
Über die FAST API wurden Webseiten dem Crawler gegeben, die bevorzugt gecrawlt und indexiert werden sollten, nachdem der Eigentümer über ein Payment Gateway dafür gezahlt hatte. Über eine GUI konnte der User seine URLs verwalten. Ich habe einen kleinen Teil der Anwendung mitgeschrieben, in PHP.